
The Wordle Bot
One question we had when playing Wordle is what the best first guess is. In order to answer this question, I realized I would have to build a bot to play Wordle "perfectly". Thus, the Wordle Bot was born.
You can test out the Wordle Bot at the link below. You decide on a hidden word, and the bot will play Wordle with a sequence of guesses that are in some sense "optimal". As an added feature, you can specify the starting word for the bot to use.
Test the Wordle Bot!
The Algorithm
The algorithm I came up with is a minimax algorithm. In simple terms, the algorithm guesses the word that maximizes the minimum possible amount of information received from the guess. So, how do I quantify the amount of information obtained with a guess?First, we define a dictionary of possible words to guess. To obtain this list, I found all 5 letter words that were in both Wikipedia's list of 100,000 most common words and an English dictionary, resulting in 3,103 possible words. This list is clearly missing some words (for example, "pesto"), but is complete enough for our purposes while being small enough to be practical.
Now, a candidate guess from the list of words is selected. Then, the algorithm iterates through all possible words in the list of possible solutions that are consistent with the information already received during the game, simulating the response that it would get for guessing that word. For example, consider the following game:
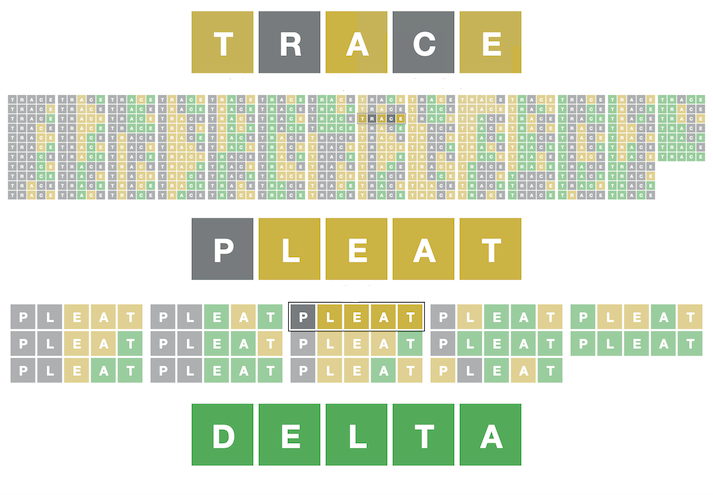
This scoring process is repeated for all possible guesses, and the algorithm chooses the guess with the lowest possible score as the best guess for this turn. This is where the term "minimax" comes from---we are minimizing the size of the largest group of possible solutions that all yeild the same response to the candidate guess. We can also describe this algorithm as "greedy" because it only looks ahead one word before making a guess. This process is repeated until only one possible solution is left. In the example above, guessing "pleat" fortunately gave us information that left only one possible solution: "delta".
In practice, all of this computation only needs to be done once. Then, the results can be saved into a tree that can be looked at on-the-fly, which is lightning fast.
The Best (and Worst) Starting Words
An estimate of the best starting word can be found by comparing the score of each word as a first guess. Using this method, I found that some of the best starting words are...Spoiler warning
reals, aloes, tails, roles, and ratesSpoiler warning
fuzzy, mummy, puppy, buggy, gummyAlternatively, we can compute the entire solution tree for each starting guess, then compare the average number of guesses needed for a random hidden word. This technique yields a slightly different set of best starting words...
Spoiler warning
tales, dares, cares, tries, taresSpoiler warning
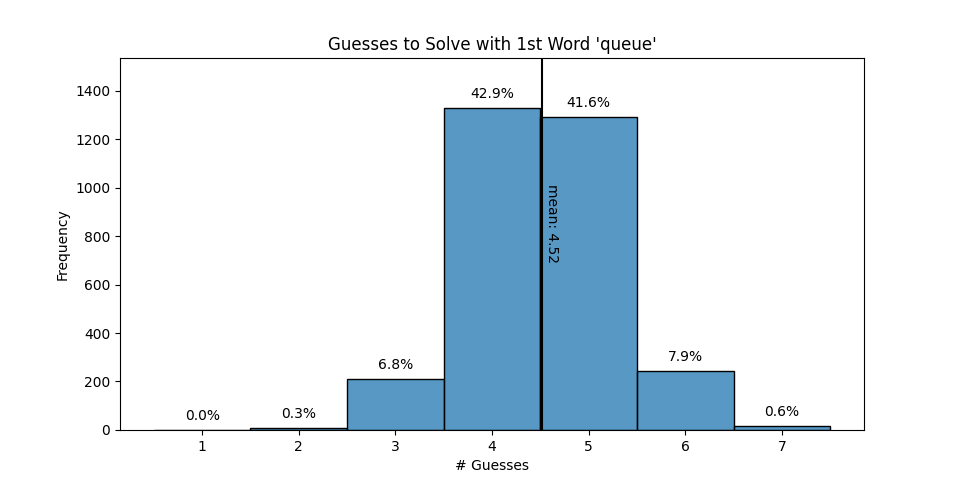
jiffy, fuzzy, mummy, mamma, queue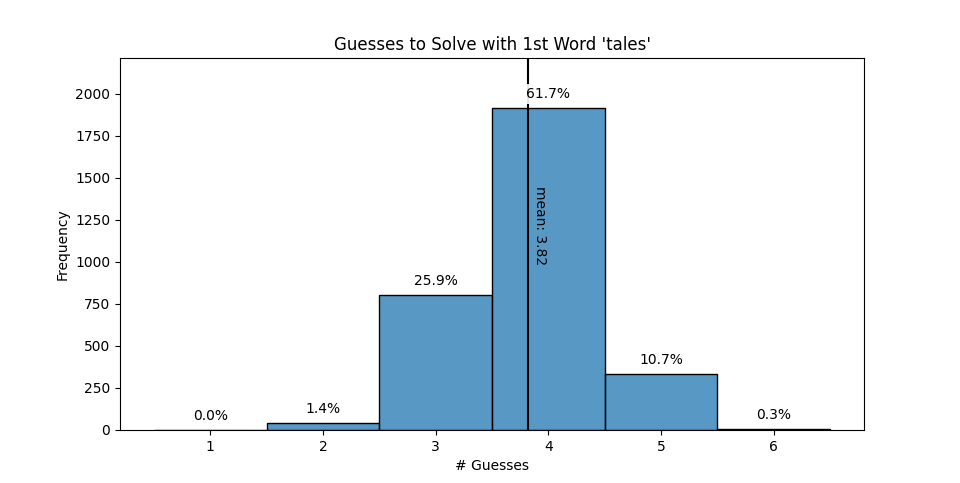
What's Next?
Perhaps the most interesting extension to this project would be a "hard mode", where the bot is only allowed to make guesses that are consistent with the information that it already has. I suspect that, unlike classic Wordle, hard mode is not always solvable in 6 guesses, even with the ideal starting guess. The algorithm described above can be easily modified to allow this (it's a one line change, in fact).The web app is currently limited to only using "tales" as the starting guess because the free server (just barely) lacks the storage space for the every solution tree. These trees could very likely be compressed to ensure they fit into the allotted disk, thereby enabling the user to specify the starting word in addition to the hidden word.
Instead of defining the score as the largest number of possible solutions that all yield the same response to the candidate guess, we could have chosen the average numer of solutions that all yield the same response. On average, this will likely perform better than our choice. On the other hand, there will likely be more hidden words that require 6 (or more!) guesses. It would be interesting to compare these algorithms.
Check out the GitHub Repo!